DeepSeek-R1之后,Kimi K2 Thinking又给OpenAI们亿点点震撼
扫一扫
分享文章到微信

扫一扫
关注99科技网微信公众号
【TechWeb】11月10日消息,“这是又一次DeepSeek式的辉煌时刻吗?开源软件再次超越闭源软件。”国际知名开源平台Hugging Face联合创始人Thomas Wolf在社交媒体上这样评价Kimi K2 Thinking的发布。
11月6日,中国AI初创公司月之暗面(Moonshot AI)推出并开源了其最新生成式人工智能模型——Kimi K2 Thinking。这款模型在多项核心基准测试中超越了OpenAI的GPT-5和Anthropic的Claude Sonnet 4.5。

而更令人震惊的是,媒体援引据一位知情人士透露,Kimi K2 Thinking模型的训练成本为460万美元,这一数字不到GPT-3训练成本的百分之一。
开源大模型正在全球AI领域掀起一场效率革命与成本风暴,而这场风暴的中心,正逐渐转向东方。
训练成本仅460万美元?小成本模型实现大性能突破
Kimi K2 Thinking的出现,彻底刷新了业界对AI模型成本与性能的认知。这个拥有1万亿参数的混合专家模型,每次推理仅激活320亿参数。
在技术设计上,它完美平衡了模型规模与计算效率,支持256k的上下文窗口,并采用原生INT4量化技术。

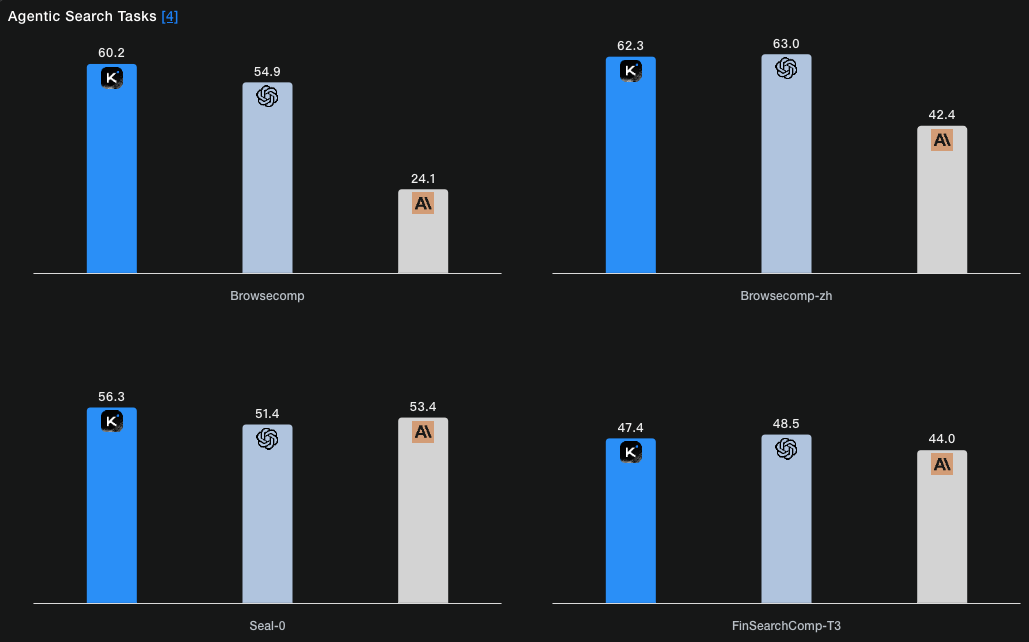
在权威基准测试中,Kimi K2 Thinking展现出了令人瞩目的实力:在Humanity‘s Last Exam中取得44.9%的优异成绩,在BrowseComp测试中获得60.2%,在SWE-Bench Verified和LiveCodeBench v6两个编码评估中分别达到71.3%和83.1%。
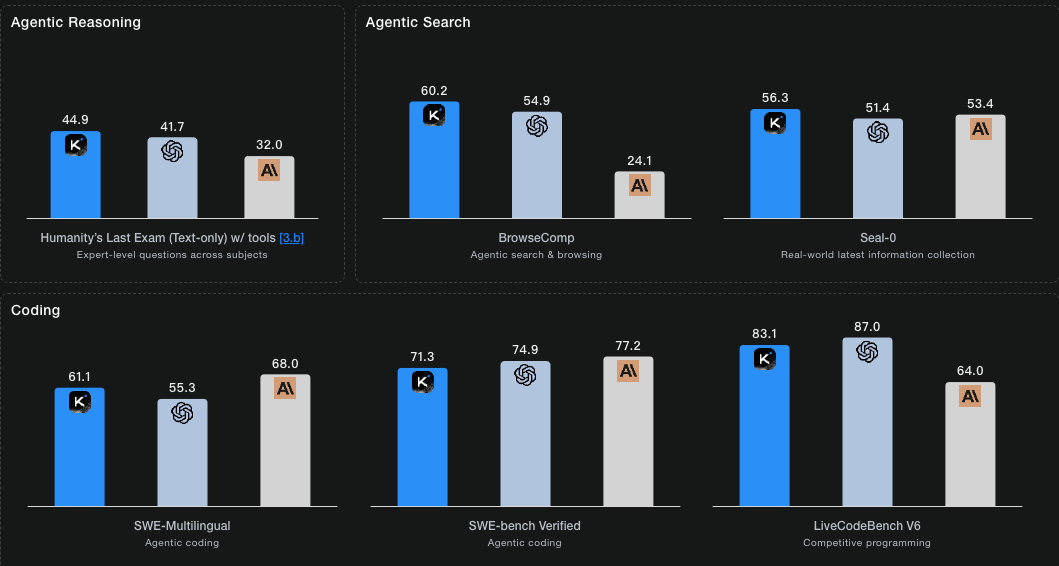
Kimi K2 Thinking模型的核心优势之一是它的Agent能力,能够连续执行200-300次工具调用,无需人工干预即可解决复杂问题。
在编程实践中,开发者只需一句指令,就能生成一个类似Mac OS的网页操作系统,具备文本编辑器、文件管理器、画图工具等完整功能。
如果说性能表现令人赞叹,那么Kimi K2 Thinking的成本控制则堪称革命。460万美元的训练成本,放在动辄数亿美元投入的大模型赛道,几乎是一个可以忽略不计的数字。
这一数字甚至低于DeepSeek V3模型的560万美元,更是与GPT-3等国际同类大模型高达数十亿美元的训练投入形成鲜明对比。
低成本的训练并未牺牲性能,Kimi K2 Thinking在保持顶尖性能的同时,运行成本也大幅降低。
Kimi K2 Thinking团队介绍,这种成本优势源于多方面的技术创新。一方面,模型采用了改进的MuonClip优化器,在长达15.5万亿tokens的预训练过程中实现了 “零损失尖峰” ,意味着训练过程极其稳定。
另一方面,原生INT4量化技术不仅将推理速度提升了约2倍,还显著降低了部署所需的GPU显存,使模型对硬件更加友好。
Kimi K2 Thinking的API调用价格为每百万token输入1元(缓存命中)/4元(缓存未命中),输出为每百万token 16元,相比GPT-5低一个数量级。

月之暗面2025年7月11日发布初代Kimi K2模型;9月5日升级为Kimi K2-0905版本,强化Agentic Coding能力;11月6日发布Kimi-k2 thinking
投稿邮箱:jiujiukejiwang@163.com 详情访问99科技网:http://www.fun99.cn



 亚马逊云科技re:Invent 2025发布Nova 2系列,多款中国
亚马逊云科技re:Invent 2025发布Nova 2系列,多款中国
在亚马逊云科技举办的re:Invent 2025全球大会上,首席执行官Matt Garman宣布推出四
快资讯2025-12-04
 iPhone 17系列立大功!苹果10月全球份额24.2%:创历
iPhone 17系列立大功!苹果10月全球份额24.2%:创历
12月4日消息,据市场调研机构Counterpoint Research最新报告,2025年10月,苹果在全球
快资讯2025-12-04








 推荐资讯
推荐资讯

